When discussing microservices and communication there seems to be a sentiment that I keep seeing crop up, which paraphrasing goes something like the following:
Microservices shouldn’t communicate with one another otherwise they lose their autonomy and that defeats the purpose of using microservices.
I can’t help but think that those who say this sort of thing are somewhat missing the point, while autonomy is important (more on that in a moment) when talking about communication the focus should be on loose coupling between services. Now don’t get me wrong, if you find that there is a lot of communication between two services this can be a smell that your modelling may not be correct, but in any sufficiently complicated system there will be some level of coupling incurred. If we go back to the sentiment that I mentioned earlier it’s my opinion that those making statements like this are often conflating autonomy and coupling, so I want to define my interpretation of those two terms in this context.
- Autonomy - If a service has the ability to run independently of any other service and if it or any other service fails it does not cause the entire system to fail.
- Coupling - Is the dependence on the implementation of a service by another. When services are tightly coupled a change in one necessitates a change in another, when loosely coupled a change in one service can be made independently of any other service.
When we consider those definitions and revisit the original sentiment I think that there are two things at play here, the first is that autonomy and coupling are being conflated and the second is the assumption that any coupling between services is tight coupling. In order for the latter not to be true there does need to be some guidelines around communication using implementation agnostic approaches (e.g. HTTP, RabbitMQ, etc). One argument that I’d like to address that is often brought up when discussing communication between services is that when one service needs to communicate you incur deployment coupling and the services will no longer be able to be deployed independently. I find this notion to be something of a red herring, there is some truth to it in that there will be deployment coupling however this is a once off scenario; Once the upstream dependency has been deployed both services can once again resume being deployed independently, in the situation where you are unable to wait for the upstream dependency there are techniques that can be used to mitigate that situation.
In the remainder of this post I want to go through some of the approaches you can take when your services need to communicate with one another.
Database
I thought we’d get this one out of the way first, there is always the option to access the database of the service that you need to interact with. I’d strongly advise not to do this as it would be tightly coupling your services together where a change to your underlying data structures could necessitate changes in multiple services and quite likely also the reimplementation of the same business logic in multiple places making changes to that logic more costly. Once you start down this path you are effectively creating a distributed monolith where you suffer from the drawbacks of both architectural styles.
Synchronous APIs
This approach sees your service interacting with the upstream dependencies synchronous APIs (e.g. RESTful API) on an as needed basis and is best used when you require data from your upstream service (which could be creating/updating/deleting its own concerns) to complete the transaction, in this situation this approach tends to be easier to implement than the equivalent asynchronous approach.
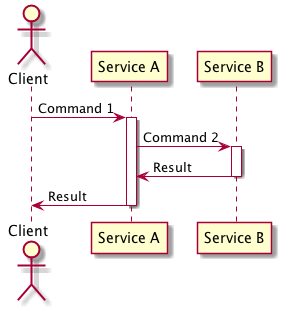
The cost of it is that you incur runtime coupling between both of you services as such they both need to be running for your service to complete its transaction, the level of complexity within a service does increase when your service requires multiple upstream dependencies to modify their concerns, careful thought needs to be given to how to handle the situation where one of the dependencies fails.
Graceful degradation
When interacting with another service via synchronous APIs it’s my opinion that you need to implement graceful degradation to be a good citizen. For those of you who are unfamiliar with the term of graceful degradation it is when you limit the functionality provided by your service when its dependencies are not available rather than taking the entire service offline. An example of this would be service A depends on service B when it is creating entity C, however it does not require service B when exposing entity C for retrieval in the case where service B is not responsive service A will continue to allow clients to perform a read however it will not allow for the creation of new entities until service B is responding once more.
Graceful degradation is a technique which you can use to get around deployment coupling, in the example above if service A is deployed before service B you may not be able to create entity C but the service can still perform any other commands which service A provides.
Asynchronous Messages
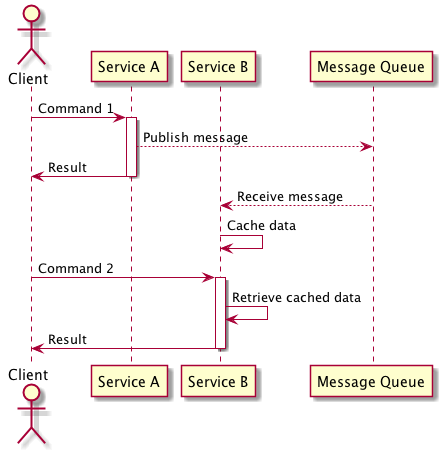
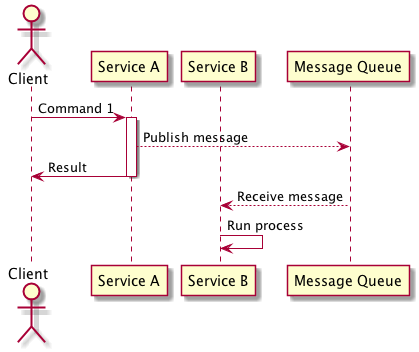
In this approach your service listens to messages published by the service that it is dependant on and upon receiving them performs the appropriate business logic, this allows a service to react to changes within another service without the burden of the runtime coupling of using asynchronous communication. In the situation where the service needs to create/update/delete an entity based on this command this approach is best suited when the result of the command is not required by the service that published the message to complete its own transaction.
In the situation where you need data from another service to complete a transaction but do not require the dependency to perform a command and latency dictates that retrieval from the upstream dependency is too slow you can use asynchronous messages to create a cache of data within your service which can be quickly accessed. The drawbacks of this approach that needs to be considered is that it does increase the complexity of your service now that it has to maintain a cache of data, this cache could contain stale data as your service may not have processed all of the asynchronous messages to bring the cache up to date.