
For better or worse you’ve found yourself in the situation where the concern you’re dealing with no longer fits in the service that it currently lives in. Whether it’s because something has changed with the concern or the initial modelling wasn’t correct is neither here nor there, these things happen. What happens next is what is important.
In this article I want to cover some of the techniques we can use when we find ourselves in this situation. For the purposes of this article I’m going to use the following definitions:
- Commands - The synchronous communication for the service used when you want your service to do something, these are commonly mapped to the CRUD actions offered out on a RESTful interface.
- Events - The asynchronous communication for the service for when you want to notify the ecosystem that something has happened in the service (usually as a result of a command or another event). These are generally offered out over a messaging technology such as RabbitMQ or Kafka.
The main scenarios that we will be covering is when the is a 1-to-1 move of the concern (lifted and shifted) from one service to another and a 1-to-many split of the concern between potentially multiple services.
Synchronisation
While this approach could fall under techniques that can be used to cater for events I wanted to address this option separately because all of the other approaches deal with moving the ownership of the concern to another service. In this approach you add the concern or concerns to their destination without removing it from the original service, then the data store for each service is populated and kept in sync by consuming the events emitted by the other services.
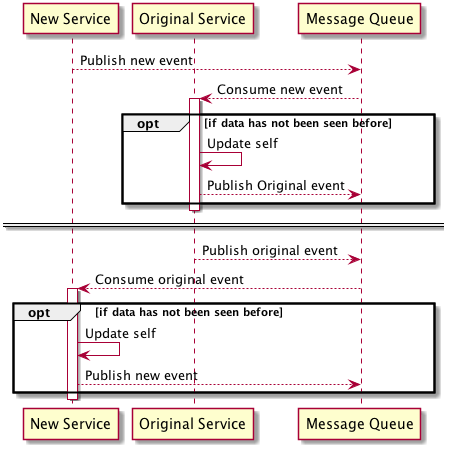
Personally I’m not a fan of this approach as it is effectively introduces dual mastery into your system and all of the complexity and issues of keeping two data repositories synchronised (e.g. what happens when one gets out of sync with the other or if one event breaks the other service?) and this only gets worse if you are splitting your concern in a 1-to-many fashion. In cases where I’ve seen something like this done I’ve found that it also leads to confusion amongst the developers in regards to which is the go forward option. The advantage of this approach is that compared to some of the others listed below the old service does not incur any run time coupling between the services as they do not need to be up at the same time.
Commands
Redirection
This approach is best utilised when commands are exposed by a RESTful API, when the service receives a request for the concern (in the example below a GET) the service will respond with the new location for concern for the client to request.
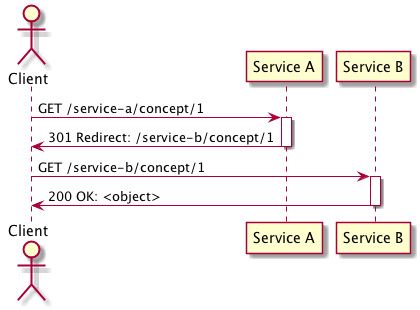
This approach is best used when the concern is either a straight lift and shift from one service to another with no changes to the contract or the new contract is a superset of the previous version as in the case with the semantics of a 301 redirect the client will be expecting the redirected request to behave the same as it previously did.
API Composition
This approach is best suited for the situation where when removing a concern from a service you split it amongst multiple services. The original endpoint for the concern becomes a facade across the new APIs that are now responsible for the sub-components of the concern, responsible for taking the results from the new APIs and transforming them into the shape that is expected from the original endpoint.
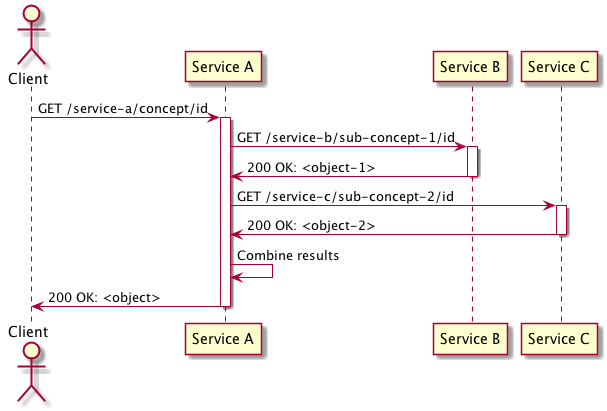
This approach is also applicable in the situation where a concern has moved between services but the redirect approach is not applicable e.g. the contract has a breaking change. In this case the original endpoint serves as an adaptor over the new endpoint transforming the request and response into the expected formats.
Events
Multi-Publish
In this approach the new service publishes both the event from the existing service and if needed a new event for the concern now that it has shifted.
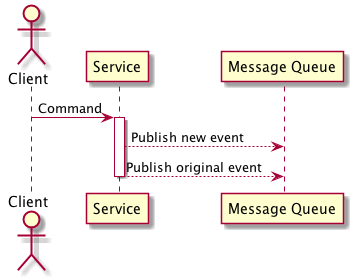
This approach is best suited when the concern has been directly lifted and shifted or when the data can be transformed into the shape of the old event when a breaking change has been made. If the case where a breaking change has been made and additional data is needed to augment the services data in order to transform it into the original shape some care needs to be taken to ensure that you don’t start leaking concerns between services.
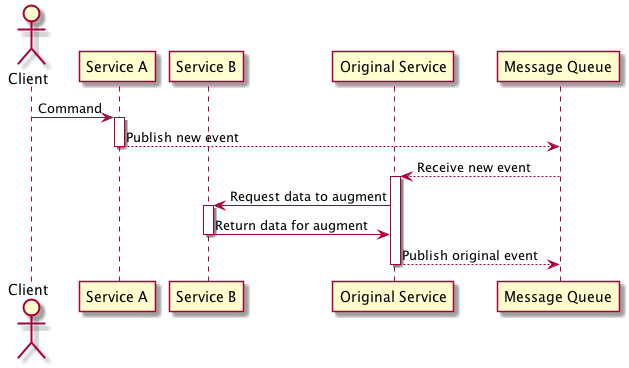
Republish
In the case where the concern has been split amongst multiple services and you want to avoid the risk of leaking concerns between services you would be better off modifying the original service to listen to the events being published for the new concerns and then retrieving the data required from the other services needed to publish the original event.
What next?
Now that the concern has been moved what are the next steps? No matter what approach you take there will be some level of technical debt incurred and at some point you need to retire the original commands and events. The simplest approach is to announce the deprecation of the concern and a date at which point it will be removed from the original service, putting the onus on the consumers of the concern. While at times this approach is appropriate it is not one that I particularly care for as this can lead to friction between yourself and the consumers due to potentially conflicting and competing priorities.
Alternatively you can maintain the technical debt until usage of the original concern dissipates. In the case of commands (especially when using HTTP APIs) which are externally exposed this can be tricky as you may not be in control of all of the clients interacting with your services. What you should have hopefully is monitoring of the usage of your APIs which you can use, when the usage of the original endpoints drop below a certain threshold the endpoints can be removed. In the case of events you can hopefully raise a technical dept with each of the consumers of the event and once those pieces of work has been completed then remove the publication of the original event.